IPv6规模化部署之门户网站IPv6支持度整改
关于《推进互联网协议第六版(IPv6)规模部署行动计划》我写过多篇博客。
- 从张焕杰的《校园网站安全防护之Nginx》说开
- 继续说IPv6、HTTPS、HTTP/2,系列完结吧
- 5分钟让你的老旧网站支持IPv6、HTTPS、HTTP/2,不能再多了
- 高等院校Web服务提供IPv6情况随笔
目前有多个监测网站在定期对IPv6规模化部署进行评估,在其中的一个平台,会以某高校门户为起点,爬取该高校所有网站内的链接,统计已经支持IPv6的网站和总网站数的比率并且公示排行。
如果你关注过,你应该知道会有“二级内链支持度”、“三级内链支持度”和“IPv6支持度评分”,分数为3个%。
定义:
二级内链支持度:在网站首页IPv6可访问的基础上,通过IPv6协议的HTTP、HTTPS请求可成功访问的网站二级内链数量占二级内链总数的百分比。
三级内链支持度:在二级内链IPv6可访问的基础上,通过IPv6协议的HTTP、HTTPS请求可成功访问的网站三级内链数量占三级内链总数的百分比。
为了做好整改工作,你可能会从某个位置拿到该平台针对你校的错误日志。会有2个文件,分别是L2.csv和L3.csv。
拿到日志后,经过分析,会有以下多个错误信息类型:
- Couldn’t resolve host name
- errmsg:xxxx,response_code:xxx
如果错误不多,直接照着错误信息整改即可,但是如果类似我们一样,一开始近400个问题,很难梳理清晰。所以我写了一个程序。源代码在最后。
因为最终看的是百分比,是不管你的网站总数的。极端一点,你全校只有一个站点并且支持了IPv6,那就是100%。
或者比如说你全校共100个网站,其中10个网站不支持IPv6,得分率会是90%,然后你很无聊,花了5分钟弄了个泛域名解析,在门户网站某个页面生成用户不可见的一千个子域名(a-X.example.edu.cn,X∈[1, 1000)),并且全部显示到一个空白的页面,完成率就会变成99%以上。但是这个是不可取的,没有意义,请忘记我说的这个。
整改方法
升级到IPv6
如果有网站不支持IPv6,可使用双栈或者反向代理让网站支持IPv6。推荐使用反向代理的模式,反向代理除了可以让网站支持IPv6外,还可以添加TLS、HTTP/2支持,同时HTTP流量统一后,对于监测、分析、日志留存也更为方便,流量也更为干净。对于服务器来说,只信任反向代理过来的访问,使得服务器在互联网隐藏起来,安全性更高。
有些比如下载站、选课等大流量高并发系统不适合通过反代发布,这时可让服务器支持IPv4和IPv6双栈来完成。
删除链接
有些链接是本来网站域名就已经失效的,但是链接还保留的,这种简单删除链接即可。
如果网站过老,已无运维能力,技术上确实无法支持IPv6,可考虑不支持IPv6但是在门户网站删除该链接。删除链接后但是又想让用户可以访问到网站有多种方式:
- 比如需要用户直接输入网址
- 比如在页面上删除链接,然后用文本提示用户如果要访问可以自行拷贝地址访问。
- 因为目前监测系统的判断只是a链接的href,
也可以通过JavaScript等其他方式实现,请自行查找,但是这个方法对SEO不友好,可能导致网站在搜索引擎内消失掉。
监测平台和整改之间的时间差问题解决
由于监测平台是使用爬虫机制对网站进行监测,如果爬取频率过高,本身平台资源消耗较大,对被爬取的网站也有一定影响,所以爬取会有一定的时间间隔,经过咨询,平台监测域名是否可解析、可访问每日均有运行,而爬取页面并且解析页面并反馈到平台时间会长一些。所以导致你整改后无法很快获得反馈。
这个从技术上可以进行改进,比如对于“错误链接所在页面”的页面内容缩小爬取的时间间隔,比如一天一次。由于“错误链接所在页面”占比很小,爬取的数量也会比较少,对平台本身和用户影响也会较小。或者有某种机制用户可以自行触发平台的爬取。
从目前来说,平台没有修改之前,我们可以自己使用程序根据错误日志使用跟平台相同的逻辑来自查是否整改完毕,并等待平台刷新。
HTTP状态码
目前监测平台对于返回是1xx、2xx、3xx、4xx暂时都算支持IPv6,而对于返回5xx算不支持。这里会有一个技术问题是,一般网站如果要进入“维护模式”,会将网站所有内容改成一个 maintenance.html 页面,并且返回503,头部返回“Retry-After 时间”,目的是告诉搜索引擎,站点目前无法访问,可在“Retry-After 时间”后重试,但是不应当修改已经缓存的页面内容。但是按目前的监测方法,返回5xx是不支持的,所以都尽量改成4xx。
有些网站会有爬虫保护,比如传递的Agent、Referrer不对,都会响应不同错误码,要注意识别出来并且整改。
常态化
由于网站状态是变化的,网站限制校内访问、访问超时、出错都会影响评分,整改只能无限接近100%,也不用追求每天都是100%。
源代码解析
首先将L2和L3 2个文件整合起来分析。对每一行,根据正则表达式拆封出存在错误的行的URL地址、错误信息和错误所在的页面。
接着根据2种错误类型,对于找不到IPv6域名的,判断目前是否已经有IPv6域名了,没有则继续判断相关“错误所在的页面”内是否已经没有这个“URL地址”了,如果还存在,则输出整改。
对于有IPv6域名,但是无法访问或者访问存在5xx错误的,判断目前“URL地址”是否没有错误了,有则继续输出整改。
以上输出是按错误的“URL地址”输出的,如果要发给各个“错误所在的页面”的网站管理员整改,必须再次梳理,以“错误所在的页面”的网站来分组输出,所以最后一个函数print_delete_links_by_domain_name按网站输出,方便发给不同的网站管理员批量处理。
代码是幂等的,可以重复多次运行观察整改进度。
结果类似下面图。
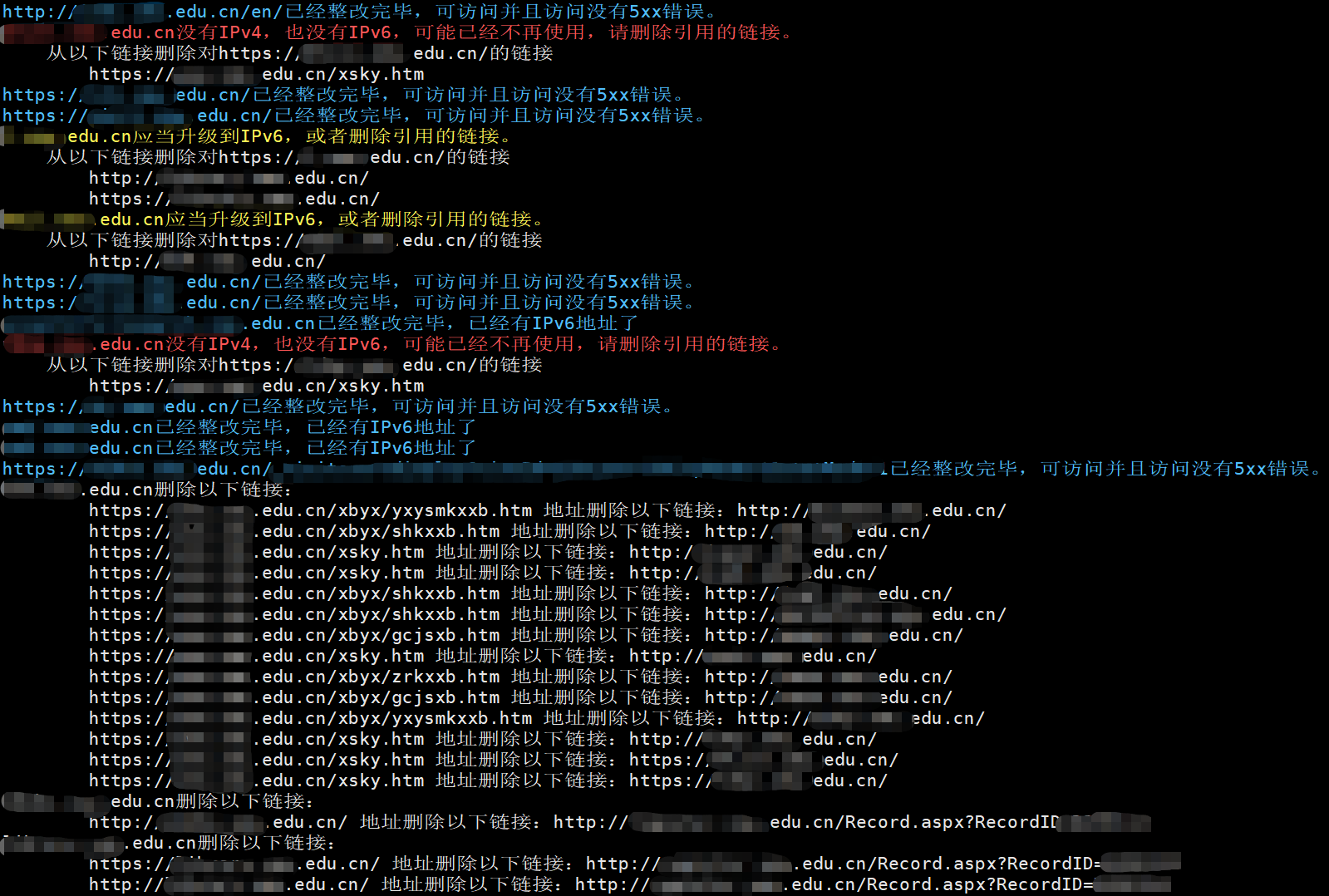
由于我们已经全部整改好了,所以代码调试不完全正确,可能存在错误,示例代码只提供思路,建议小调整。如果整改后还是存在偏差,请人工核查。
代码
#!/usr/bin/env python3
import re
import socket
from urllib.parse import urljoin, urlparse
import requests
from bs4 import BeautifulSoup
from config import L2_FILENAME, L3_FILENAME
COULDNT_RESOLVE_HOST_NAME_MSG = "Couldn't resolve host name"
class FONTCOLORS:
INFO = "\033[94m"
WARNING = "\033[93m"
FAIL = "\033[91m"
ENDC = "\033[0m"
def has_ip_addr_by_socket_get_addr_info(domain_name, inet):
try:
_ = socket.getaddrinfo(domain_name, None, inet)[0][4][0]
except socket.gaierror:
return False
else:
return True
def has_ipv4(domain_name):
return has_ip_addr_by_socket_get_addr_info(domain_name, socket.AF_INET)
def has_ipv6(domain_name):
return has_ip_addr_by_socket_get_addr_info(domain_name, socket.AF_INET6)
def is_link_in_content_href(link, url):
# return True
if not url:
return False
try:
page = requests.get(url, timeout=10)
except (
requests.exceptions.ConnectionError,
requests.exceptions.HTTPError,
requests.exceptions.InvalidSchema,
requests.exceptions.BaseHTTPError,
requests.exceptions.ReadTimeout,
):
print(f"{FONTCOLORS.FAIL}url get error. {url}{FONTCOLORS.ENDC}")
return False
page.encoding = page.apparent_encoding
soup = BeautifulSoup(
page.content, "html.parser", from_encoding=page.apparent_encoding
)
hrefs = soup.find_all("a", href=True)
for href in hrefs:
href = href["href"]
href = urljoin(url, href)
if href == link:
return True
return False
def is_http_status_code_normal(url):
if not url:
return False
try:
page = requests.get(url, timeout=10)
except (
requests.exceptions.ConnectionError,
requests.exceptions.HTTPError,
requests.exceptions.InvalidSchema,
requests.exceptions.BaseHTTPError,
requests.exceptions.ReadTimeout,
):
return False
return page.status_code // 100 != 5
def get_those_from_link_still_exists(url, from_links):
result = []
for from_link in from_links.split(";"):
if not from_link:
continue
if is_link_in_content_href(url, from_link):
result.append(from_link)
return result
def get_l2_l3_file_contents():
file_contents = []
with open(L2_FILENAME, "rt") as f:
file_contents += f.readlines()
with open(L3_FILENAME, "rt") as f:
file_contents += f.readlines()
return file_contents
def get_error_url_data():
error_urls = []
for line in get_l2_l3_file_contents():
m = re.search(
r"^([0-9/ :]+),(?P<url>.*?),(?P<http_status_code>\d+),(?P<is_support>\d+),(?P<contents>.*?)$",
line,
)
if not m:
continue
url = m.group("url")
is_support = m.group("is_support") == "1"
contents = m.group("contents")
domain_name = urlparse(url).hostname
if not is_support:
m = re.search(
r"^errmsg:(?P<error_msg>.*?),response_code:(?P<http_status_code>\d+),*(?P<from_links>.*?)$",
contents,
)
if m:
error_msg = m.group("error_msg")
http_status_code = m.group("http_status_code")
from_links = m.group("from_links")
error_urls.append(
{
"url": url,
"domain_name": domain_name,
"error_msg": error_msg,
"http_status_code": http_status_code,
"from_links": from_links,
}
)
m = re.search(
r"^" + COULDNT_RESOLVE_HOST_NAME_MSG + ",*(?P<from_links>.*?)$",
contents,
)
if m:
error_msg = COULDNT_RESOLVE_HOST_NAME_MSG
http_status_code = 0
from_links = m.group("from_links")
error_urls.append(
{
"url": url,
"domain_name": domain_name,
"error_msg": error_msg,
"http_status_code": http_status_code,
"from_links": from_links,
}
)
return error_urls
def print_still_exists(url, still_exists):
print(f" 从以下链接删除对{url}的链接")
for item in still_exists:
print(f" {item}")
def print_delete_links_by_domain_name(delete_links):
delete_link_by_domain_names = {}
for item in delete_links:
for from_link in item["from_links"]:
domain_name = urlparse(from_link).hostname
url_to_delete = delete_link_by_domain_names.get(domain_name, [])
url_to_delete.append({"url": item["url"], "from_link": from_link})
delete_link_by_domain_names[domain_name] = url_to_delete
for domain_name, url_to_delete in delete_link_by_domain_names.items():
print(f"{domain_name}删除以下链接:")
for item in url_to_delete:
print(f" {item['from_link']} 地址删除以下链接:{item['url']}")
if __name__ == "__main__":
delete_links = []
for error_url in get_error_url_data():
url = error_url["url"]
domain_name = error_url["domain_name"]
from_links = error_url["from_links"]
if COULDNT_RESOLVE_HOST_NAME_MSG == error_url["error_msg"]:
if has_ipv6(domain_name):
print(
f"{FONTCOLORS.INFO}{domain_name}已经整改完毕,已经有IPv6地址了{FONTCOLORS.ENDC}"
)
else:
still_exists = get_those_from_link_still_exists(url, from_links)
if not still_exists:
print(
f"{FONTCOLORS.INFO}{domain_name}已经整改完毕,已经删除全部页面链接了。{FONTCOLORS.ENDC}"
)
else:
if has_ipv4(domain_name):
print(
f"{FONTCOLORS.WARNING}{domain_name}应当升级到IPv6,或者删除引用的链接。{FONTCOLORS.ENDC}"
)
else:
print(
f"{FONTCOLORS.FAIL}{domain_name}没有IPv4,也没有IPv6,可能已经不再使用,请删除引用的链接。{FONTCOLORS.ENDC}"
)
print_still_exists(url, still_exists)
delete_links.append({"url": url, "from_links": still_exists})
else:
if is_http_status_code_normal(url):
print(f"{FONTCOLORS.INFO}{url}已经整改完毕,可访问并且访问没有5xx错误。{FONTCOLORS.ENDC}")
else:
print(
f"{FONTCOLORS.WARNING}{domain_name}存在错误,请确认网站服务是否正常,或者删除引用的链接。{FONTCOLORS.ENDC}"
)
still_exists = get_those_from_link_still_exists(url, from_links)
if still_exists:
print_still_exists(url, still_exists)
delete_links.append({"url": url, "from_links": still_exists})
print_delete_links_by_domain_name(delete_links)