Never Trust User Input,搜索和网站内容的Injection
昨天参加了由CERNET组织的,和清华大学网络研究院网络和系统安全研究室老师们的一个视频会议,他们介绍了一种新的内容注入的问题:
这次发现的主要问题:站内搜索功能可以高效的帮助网站用户搜索特定站点内的资源,已经被广泛应用于不同类型的网站上,包括政府网站、学校站点等。然而,一部分重要网站的站内搜索功能实现不当,成为互联网地下黑灰产的推广途径。研究发现,攻击者可以在短时间内,借助重要网站的站内搜索服务生成大量含有非法产业内容的搜索链接,进一步通过将这些链接分发至搜索引擎,进一步污染搜索引擎的页面。攻击者滥用重要网站在搜索引擎中的声誉,将非法内容展示给用户,甚至可以在2个小时内实现非法内容对搜索引擎首页的霸屏效果。
然后他们还开发了一些工具来找到受到这些影响的高校的网站。
这个问题确实是存在的。
Pharma Hack
Pharma Hack是一种黑客攻击手法,针对网站CMS平台。这种攻击的目的是通过操纵网站的内容,将非法内容嵌入到网站页面中,以提高这些非法内容包括的链接在搜索引擎中的排名。
这个我们就比较常见了,以往有些CMS存在漏洞,或者内容管理员密码泄露,会在某个隐蔽的目录里,有上万个页面,页面里面是各种链接。
但是上面说的这个跟Pharma Hack有些区别。Pharma Hack是攻陷了你的网站,所以他的内容会有大量的链接,主要是利用你的高Rank来抬高他们那些链接的Rank。而这种攻击,因为注入的只能是文本,不能是链接,所以他的目的主要是利用你的高Rank,在搜索引擎里面把他内容展示出来。
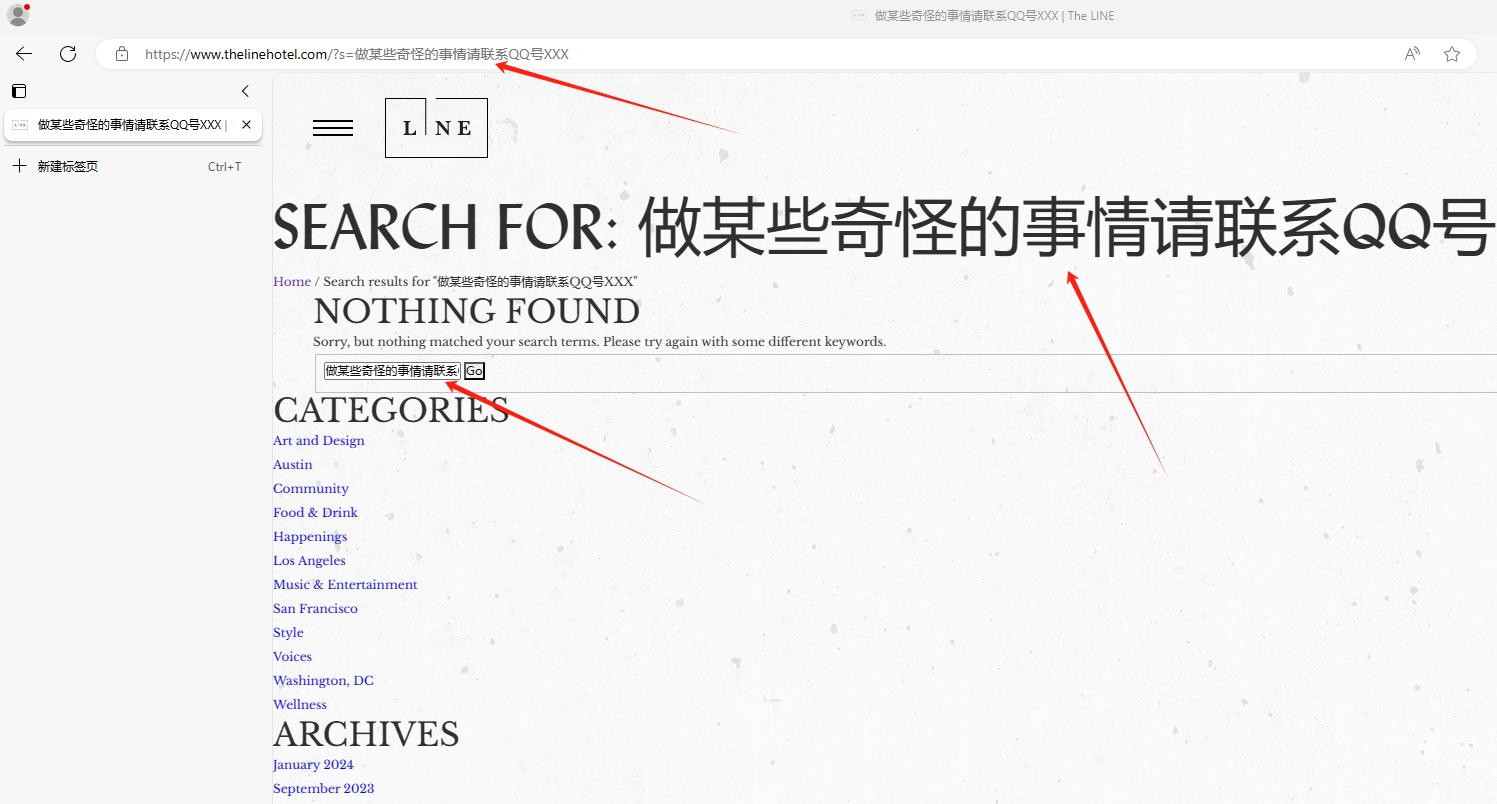
所以说这种比Pharma Hack稍微轻微一点,但是由于现在URL重写技术大量利用,导致你很难一下子就可以从链接来确认人家是Pharma Hack还是上面这个攻击。比如上面截图的“做某些奇怪的事情请联系QQ号XXX”,监管部门看到就会以为你这个站点已经被攻陷,被恶意用户植入了恶意代码,但是这个其实只是浏览器URL里面的某个字符转换而成输出的内容。
这会带来什么后果?如果用户在搜索引擎搜索“奇怪的事情”,你的网站Rank比较高,则会出现在搜索页面。因为直接提供“奇怪的事情”的网站可能自身已经被搜索引擎降权了。
如果搜索引擎自身有一些算法,他会看到他所收录的你的网站都是些什么鬼,会将你降权,导致仿冒网站可能比你排名还高。也就是,搞仿冒网站的人可以利用这个方法把你的Rank打下来。
而且搜索一般资源消耗比较大,如果恶意用户构造了很多搜索链接,可能对你的网站造成DDoS攻击。
一两年前,我们在一个访问量比较大的WordPress网站上发现了这个问题,后面没有去研究如何改POST,就直接将搜索禁用了事。
目前已知的修复方法有
robots.txt禁止
Disallow: /search?query=*
这个可以禁止一些搜索引擎,但是清华老师也提到,这个无法阻止直接诱骗搜索引擎访问链接,如果搜索引擎不遵守robots.txt的规则的话。
对部分搜索关键字进行过滤
对某些搜索关键字进行过滤,但是这个过滤名单可能很长。
改成POST请求
POST请求应该可以一劳永逸解决这个问题,但是在实现上存在一些问题,比如某网站群,首次是POST的,但是在下一页的位置,又是简单构造了GET的请求。某网站群,搜索后会生成一个Token from Search Results,URL不带BASE64编码或者明文搜索关键字,这个Token from Search Results会保留在数据库里,主要是为了搜索加速,方便进行分页,这个Token from Search Results如果有效期有问题,也会导致问题还会继续。
将结果返回改成404
这个是,如果搜索结果不存在,将HTTP的状态码改成404,但是页面还是原先不变,这样子对用户比较友好。即使通过诱骗搜索引擎发现这个假的链接,搜索引擎也会忽略内容。但是监管部门或者一些扫描设备不一定会忽略。
将不存在的结果文本删除
这个是在搜索结果时,如果搜索结果不存在,则不显示“XXX”不存在,而是直接说“你所搜索的内容不存在”,但是这个对用户不够友好,因为很多时候搜索,我们可能只是写错了某个字,需要根据搜索结果调整关键字,如果不显示,则还需要重复输入整个搜索关键字。
可能是一个更大的问题
我后面意识到,这个其实不只是搜索的问题,有可能存在更大的范围,也就是,如果你的网站存在用户输入的内容并且会回显给用户,如果这个可以使用GET请求或者说没有屏蔽GET请求,如果这个不需要登录验证,那就会存在这个问题。而我们知道,很多后端编程语言实际上是不会去区分GET还是POST。我们以某大家都在使用的邮件系统为例,在用户名里输入“我是某个奇怪的词”,并且以GET请求,因为这个邮件系统的Form是没有CSRF保护的,所以会正常请求并且返回值会包括
<input placeholder="用户名" value="我是某个奇怪的词" class="u-input" type="text" name="uid" autocomplete="off" id="uid" tabindex="1"/>
这就非常麻烦了,在Web安全编程里,在所有编程里,我们都被教育“Never Trust User Input”,这导致需要对网站的所有输入输出进行审查,以往我们从技术上更加关注反射型XSS问题,现在,我们还需要关注,除了对XSS攻击进行HTML编码外,还需要关注回显给用户的内容的安全问题。
开始整改吧!