厦门大学免费米饭统计,我是如何填坑的
文章目录
- 文章目录
- 为什么要做这个免费米饭统计
- 免费米饭历史
- 存在的问题
- Elasticsearch尝试
- 自己写ETL
- 批量bulk写入
- 换实体机
- 横向扩展ES
- 换index
- Mongodb
- 最差方案
- 换Mongodb3
- 数据reheat
- 前端
- 信息门户登录
- 微信分享
- 扔出来测试
- 系统架构图
- 关于填坑
- 写在最后
- 引用
为什么要做这个免费米饭统计
为什么要做这次可视化查询,来源于一次突发事件,6月16号晚上8点,突然接到电话,有人在使用模拟登陆抓取我们的免费米饭消费记录。于是开始介入分析,监控系统提示Linux虚拟主机报警,信息门户首页访问错误,免费米饭消费记录查询页面响应速度慢,通过分析微信分享的地址,发现代码就放在我们Linux虚拟主机里。由于看到了源代码,看到确实开发者没有恶意记录密码,也没有像携程那样子把密码Log起来调试,暂时放下了心。第一时间把代码目录改名,恢复各个系统。在分析代码时发现短短2个小时已经有至少6k人提交了自己的账户名和密码,可能由于访问的网址确实是厦门大学校内的域名导致大家完全信任了开发者。于是考虑如何在有效渠道广播通知大家保护自己的密码不在第三方系统内输入。突然灵机一动,不是粗暴把微信分享页面给干掉,而是改成密码提示页面,这样子相当于利用了这次事件提醒了所有人。好机智。
关于妥善保存统一身份认证密码的通知
近期发现有部分学生在除了厦门大学统一身份认证站点以外的其他站点输入了自己的学号和统一身份认证密码,此行为有可能导致你的厦门大学统一身份认证密码被保存,由于厦门大学统一身份认证为师生登录所有信息系统的统一密码,所以有可能导致对方网站开办者以你的身份执行你在其他系统的操作。请大家认准输入统一身份认证的页面的网址,确认为厦门大学官方网站才可输入。目前以下网址是安全的: 从信息门户 http://i.xmu.edu.cn 跳转到的 http://idstar.xmu.edu.cn/ 为安全网站。
http://i2.xmu.edu.cn 为安全网站。
http://ids.xmu.edu.cn 为安全网站。
http://open.xmu.edu.cn 为安全网站。
如你已经在其他非授权站点输入过密码,请立刻更改密码。
本通知持续更新中。
鉴于同学们对于“你在厦大吃了多少米”有极大的热情,信息与网络中心今后将适时推出统计和微信分享功能,敬请期待。
最后一句话,我给自己挖了个坑。下表。
事后才知道是因为某个学生帮忙通识教育中心开发网页,于是附带把自己的代码放到虚拟主机内。技术上是通过用户提交统一身份认证密码模拟登陆抓取数据。由于查询速度很慢,所以采样3个月的消费数据估算全部记录。计算结果在文件系统做了cache。但是程序没有队列,没有控制访问速度,导致短时间免费米饭查询承受不了出错。信息门户出错是因为他去抓取显示的用户的姓名。
我在更改完页面立刻给开发者留的邮箱写了封邮件,但是没有收到回复。开发者还写了个朋友圈,发了个公众号文章,炫耀把厦门大学信息化系统搞崩溃了。说实话,要搞死学校的信息化系统确实很容易,虚拟主机里面的一个死循环,没有控制速率模拟登陆信息门户,某个正常事件引发的类DDOS请求,都可能造成系统出错。由于软件架构的问题,我们也只能遇到问题具体分析寻找对策。在大平台没有很大改进之前很难应对这些事情,因为系统几年前开发时候是没有考虑极端情况的,而类似教务处选课系统,需求上我们就知道会有很多人会抢课,并发量大,由于有考虑到,软件我们让厂商做了预处理、索引、cache、排队,硬件我们部署了十几台服务器支持,所以我们就可以承受选课和四六级带来的压力。
免费米饭历史
“免费米饭”由朱崇实主导,从2008年起,厦门大学向全校全日制学生提供免费米饭。当时,面对上涨的物价,很多贫困学生压力很大。“如果基本生活条件无法保证,又怎能安心读书?”朱崇实对此有着切身的感受,学生时代的他也常吃不饱饭,“我现在所做的,就是我当学生时候想做,而做不了的。”
上面是搜索来的免费米饭介绍。2008年学校要开始提供免费米饭,一卡通厂商负责POS机改造和数据写入数据库,而大家现在看到的那个免费米饭查询,正好我也参与了开发。所以,我必须来填这个坑了。虽然你们看到的查询很简单,实际上还有各个商户每个月每年的统计报表,财务处的报表等等。可能有些人认为为什么需要让学生可以查免费米饭消费记录,把整个查询系统放到内网,当成管理端,安全性更高,然而我对数据是很敬畏的。我希望每个人对自己数据都是可视的,虽然这个数据完全没有运营商网络流量涉及到计费的切身利益问题。幸好是我自己开发的,所以就把这个页面放出来了。
当然,填坑不是那么好填的。
存在的问题
- 生产库不敢直接跑统计。我们原先有把生产库视图提供给第三方,第三方写了个错误的统计语句,运行后程序无响应,第三方就停下来继续修改,然而实际上无响应在后端导致我们一卡通出问题,查找了好久,最终在慢查询定位到问题,联系到他们时第三方完全不知道这个的影响。所以那时的情形是,问题很难重现,不定期出问题,其实每次是第三方按了个按钮,我们就死,很有画面感。
- 生产库数据库格式定义固定,不能修改schema,不能添加index。生产库上日期和时间2个字段分开,日期是以字符串存储的,有做索引,学号没有索引。
- 生产库没有自增长ID,而且由于部分商户离线消费,上传数据不及时。
- 2008年数据量少,查询速度还是很快的。几年下来积累了几亿的数据,简单的限制40天的查询速度都很慢。
Elasticsearch尝试
决定了要填坑,而且受制于原先系统的问题,于是考虑研究如何解决,我的希望是使用大数据引擎,达到实时分析的效果。我不想去用Oracle,上古时代的技术,于是想到了Elasticsearch。ES原先有用过,在校内分析DNS Log时,每天40G,3亿条数据,速度很理想。
自己写ETL
ES有自带数据库的ETL。然而生产库没有自增长ID,而且我想控制Load速度,所以只好自己用Python写起ETL来。保留按日期来Load和删除的能力,还要过滤一下商户名称,拼接消费时间。
ETL写好了,跑了次,写入速度每秒500个,有点慢,整个数据Load进去要几天。
批量bulk写入
找了资料,换成批量写入,上到3千。然而在查询的时候非常慢,一千万条记录搜索一个人的消费记录要1x秒。速度不可接受。
换实体机
又查资料,查询速度应该不会这么慢,怀疑是IO问题,于是在研发部群里讨论了虚拟机IO问题,找许卓斌要了台实体机来测试,速度快了,但是还是没有达到预期,全量几个亿上去,速度更慢,而且系统Load非常高,如果人一多,肯定杯具。
横向扩展ES
于是横向扩展ES到5台,速度没有改善。
突然想起来,每个人4年记录也就最多3*365*4=自己算条,然而每次查询必须去每个index每台去获取。所以速度很慢,于是考虑换成以学号做index,这样子每次查询只要找一个index即可,肯定飞快。
换index
然而学号做index,distinct的学号有20万,ES index多了,写入速度变成每秒只有20条,bulk写入也一样,虽然查询快了,但是Load很慢,不可取。
Mongodb
ES路走不了,于是考虑更换数据库,找了何伟平咨询,tony认为这是关系型数据库可以搞定的事情,但是我不想去用Oracle,不想MySQL去自己手动分表拼接,于是尝试NoSQL的Mongodb。重写了ETL,每天数据导入7秒就可以完成,然而查询的时候还是需要1x秒。考虑横向扩展,如果一千万条记录速度很快的话,我可以以学号做sharding key,开十几台服务器。让每个人都以为自己只淹没在一千万条记录而不是几亿记录里面。于是干掉数据库,重新只Load一千万条记录。(你说既然你有全量数据,把数据删除到一千万条不就好了?相信我,直接drop数据库重新Load数据比一条条find接着delete速度快一千倍),然而测试下来,一千万条记录速度还是1x秒,系统Load还好很低。通过查询Mongodb的查询explain,所有数据都是根据index获取,理论上查询复杂度在o(1),为什么速度还是这么慢,于是iostat、iozone3、bonnie++分析IO,估计瓶颈在IO上。于是考虑再换实体物理机。在物理机上部署,查询速度还是无法提高。整个全量数据50G,查询还是慢。
然而发现一个奇怪的现象,就是同样的查询,第一次查询速度很慢,第二次查询速度飞快,查了Mongodb的存储机制,发现Mongodb会把数据文件映射到内存中,完全交由操作系统处理,他本身不控制数据是在磁盘还是内存里。所以如果数据量小一点,可以把整个数据放到内存cache起来。然而50G的数据量太大,除非sharding到几台机器上。
最差方案
这时候我开始考虑如果速度上不去,但是还是要提供这个查询,是否有其他一些方法:
- 如果速度再上不去,我可以考虑引入队列,每个人点击以后,喝杯咖啡回来再看记录。
- 我也可以选择每天晚上默默对每个人进行统计。由于无法估算热点,只能全部人统计,好浪费。
- 我也可以在ETL的时候把学工号的数据拼接,3*365*4=不知道自己算条记录而已,速度也是很快的,然而这样子最终的统计完全必须自己写,用不到Mongodb强大的聚合函数。
换Mongodb3
突然发现3个月前出的最新Ubuntu 16.04 LTS自带的Mongodb版本有点低,于是尝试换成官方源安装,数据Load进去后,发现Mongodb3引入了压缩机制。原先50G的数据,使用snappy压缩完只有1xG。可以放到一台机器的内存跑了,省了好多事。据说zlib压缩模式更好,不折腾了。
数据reheat
通过重启后cp把整个数据全部cache到内存,于是速度上去了,查询结果不到1秒。
前端
后端技术准备差不多了,开始做前端展示,同事江晓莲写了个前端Web。拍了脑袋,做了小调研,于是有了下面的截图。本想加入好基友好闺蜜的分析,通过分析5分钟同时在一个食堂消费最多相关的人展示,把每个人消费时间序列向量化,通过时间按年按月比对把每个人需要跟20万的人的计算量减少到几千再进行精算出结果,某天上班时遇到大数据专家洪文兴请教了下,要采样要平滑,时间和地点可以分成2次计算,有点复杂,可能还要调参数,目前看来暂时臣妾做不到啊,留待以后了。
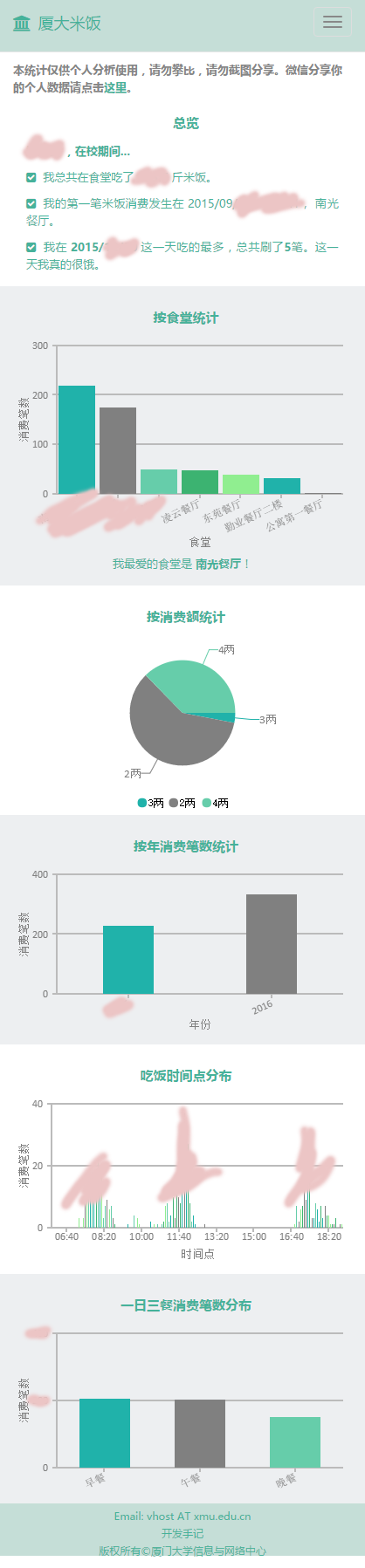
信息门户登录
用上信息门户登录我心里是没底的,原先我们的信息门户统一身份认证由于架构设计的原因,性能非常弱,每个页面都需要去中心获取登录状态,而且开发语言支持很少,我曾经做过2个包装,一次包装成WebService,一次包装成OAuth2,这段时间正好是我们信息门户旧版升级到新版的过程,正好利用新的信息门户CAS认证,也相当于是对信息门户的一次压力测试,如果访问人多的话。
微信分享
考虑到微信分享和隐私的问题,做了个简单的分享页面,懒得去申请微信开发者ID,直接用系统自带的菜单分享了。
扔出来测试
设置了 http://7.xmu.edu.cn 的域名,把系统推出来测试了,有任何意见或者建议技术架构方面的或者需求方面的请给 vhost AT xmu.edu.cn 写信。为了向上次事件致敬,保留了“你在厦大吃了多少米”文字。
系统架构图
所以这就是整个系统的架构,用到了Ubuntu,Python,Flask,Apache2,Redis,Mongodb,CanvasJS,Bootstrap,Jquery,Bower等开源软件。架构图以后画。
关于填坑
填坑过程中也踩了好多坑,如果一开始就用Mongodb,最新版,实体机,可能就没这么多事,只能怪自己技术储备不足,留待下次了。其实我还是蛮喜欢ES的,横向扩展方便,配合Kibana,是分析时间序列Log的利器。全量数据Load进去,就可以很方便绘制上帝视角的统计图表,等个十几秒,其实也无所谓,还有,ES更强大的功能是在于文本分析方面。
写在最后
有人提到信息化的API的开放问题,其实我们一直有在研究API开放,研究API网关,在API前端拦截做统计、鉴权、授权、限制速率等等,然而目前还没有时间表。是否开放有很多问题需要考虑,比如这次,如果有了免费米饭开放数据,而且数据粒度很小,即使有学生主动授权机制,然而学生的热情这么高,开发者实际上很快就可以拿到全量数据。这也是我们担心的。也希望有大数据分析技术实践经验、Web开发技术、网络安全的同学能够以各种方式参与到学校的信息化建设过程中来,最好不是这次这么突然的袭击。
引用
ElasticSearch http://elastic.co/
MongoDB与内存 http://huoding.com/2011/08/19/107
FLASK使用小结 http://www.wklken.me/posts/2013/09/09/python-framework-flask.html#session
使用Python操作Redis http://debugo.com/python-redis/